In the last few years, A.I. has become quite remarkable. It can now pilot cars and airplanes; beat humans at chess and go; handle phone calls like a person, down to the “ums” and “ahs”. It’s easy to assume that in the near future, the world will be run by smart robots – at home, at work and everywhere in-between. More info about Kirik: http://bit.ly/2Ke0sWo
But things aren’t so simple. So far, the A.I tech we have – A.I 1.0 – has run into an array of problems and limitations. Specifically:
- Overfitting. Overfitting is when the A.I gets too much data to make future predictions accurately. For example: if existing data corresponds to a curve very closely, off-the-curve data points will be ignored.
- The black box problem. If current A.I. technology makes a mistake, humans can’t intervene to improve results. The inner workings of such systems are far too complicated for human understanding.
Going from A.I 1.0 to A.I 2.0 using semantic modeling
With these limitations, A.I is likely to make a mistake sooner or later. Once this happens, humans can’t do anything to fix the mistake – and the programming led to it.
This really limits what A.I technology can do. The industry’s consensus is that we need A.I 2.0 to move forward. And today, we’re going to talk about what makes A.I 2.0 different from A.I 1.0.
An Example of A.I 1.0
SPAM isn’t a modern problem. Around 20 years ago, there was already so much SPAM that people needed A.I’s help to process it. Here’s how that work.
Developers used the Naive Bayes Classifier, based on Bayes’ mathematical theorem, to divide incoming letters into classes. These classes were sorted by content and their technical information (e.g. time of sending). If a letter was labeled as SPAM, it was moved to a separate folder.
Sounds good in theory – but in practice, this didn’t work too well. Sometimes, SPAM made it through to people’s inboxes; other times, good e-mails went to SPAM.
(A problem you probably still run into 20 years later!)
Now here’s the shocker. Today’s machine learning methods are still based on mathematical models from the 70s. A.I can look modern on the outside – but it’s actually decidedly old-fashioned. Here’s how machines learn in a nutshell:
- Events have happened and we measured them; now, we have some amount of past data. For example: let’s say we have a database of purchases for the last 12 months.
- We want to turn this data into a function that lets us predict future purchases accurately. In other words, we’re making a formula that tells us what people are going to buy – and when.
Next, we use mathematical algorithms and programming libraries to get the job done. Visually, the process might look like the images below:
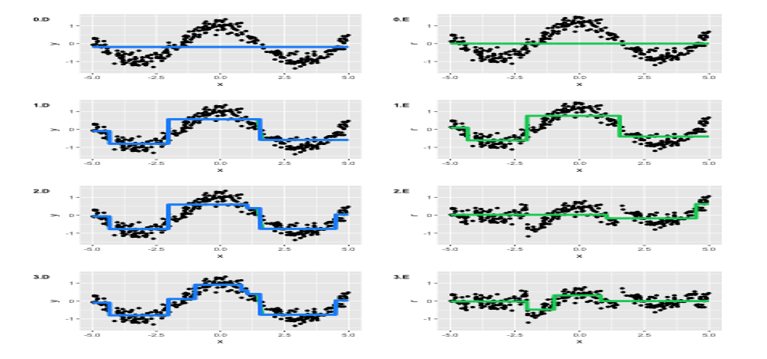
That’s right: machine learning is simply finding functions that fit real-life figures. These can be polynome coefficients, matrices with data values, or something else. The point is that we find functions and formulas that fit past events and predict future ones.
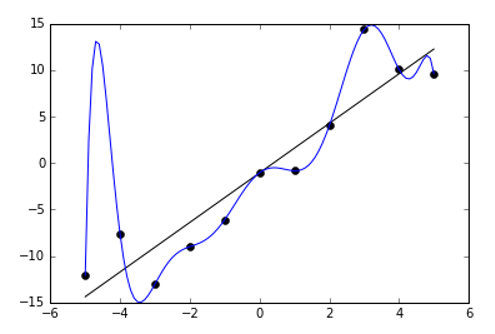
In the images above and below, you can see some examples of overfitting. This is one of the biggest problems in A.I. today. When it happens, formulas can completely fail to predict future results.
At this point, you may want to say: alright, if this is such a big problem, how are A.I. apps getting more and more advanced? Aren’t you contradicting yourself?
We’ll answer by making an important distinction. Of course there’s progress. But thus far, there have been no breakthroughs in A.I technology and theory in decades. All the applications we see are built on the above model.
The same applies to neural networks: complex A.I 1.0 applications that turn vast amounts of past data into effective actions and decisions.
The problem is that, at this point, neural networks are extremely complex. Machine learning hasn’t changed since the 70s – so developers have found ways to amp up its power.
They do this, for example, by using multiple formulas simultaneously; by using tensors rather than matrices; by creating multi-dimensional predictive models.
The problem is that the more complex A.I 1.0 gets, the harder it is to edit formulas manually. Every additional process makes the code less comprehensible to developers. This is the “black box problem”: the idea that what’s going on inside an A.I 1.0 app can’t be understood nor edited by real humans.
The Black Box Problem
Modern neural networks are a closed, black box; humans can neither see nor change what’s going on inside them.
This is a problem. If a neural network learns to deliver the wrong results, we can’t retrain it manually. Instead, we need to reprogram it from scratch; a process that can take months.
For example, in March 2016, Microsoft launched an A.I 1.0 bot named Tay. The bot “lived” on Twitter, and was announced with much fanfare. Unfortunately, users managed to teach Tay to make racist, hateful announcements in under 24 hours – and the experiment had to be stopped.
It’s noteworthy that Microsoft didn’t come back to this experiment. There have been no further attempts to introduce a machine learning chat app to the world. It’s not that Tay or Microsoft are at fault, but imagine if Tay was a machinegun-wielding policebot, a-la Robocop. That’d be a disaster, right?
Right!
And that’s exactly why we can’t use A.I 1.0. It’s nobody’s fault when things go wrong with machine learning – but they do go wrong, and there’s not much we can do about it.
We’re not saying that A.I 1.0 is a problematic technology on the level of SkyNet, but the problems are real – and very limiting!
The only way forward is to end the Black Box problem by moving to an altogether different paradigm and technology with A.I 2.0.
Artificial Intelligence 2.0
The black box problem is simple. A.I 1.0 machine learning doesn’t allow for human programming. We can neither see nor control what A.I 1.0 does.
This doesn’t mean A.I 1.0 is mute. Robots understand each other, machine commands, code, meter readings and database records. But this is all “machine talk” that’s completely divorced from human understanding. Even an advanced programmer needs time and effort to interact with A.I 1.0.
This is why we need to create a language that both humans and A.Is can understand. Getting over this hurdle is the next big thing in digital. And with the advent of IoT technology, it’s also the next big thing in manufacturing and other sectors.
And as luck would have it, the mathematical foundation for this great leap forward already exists.
Back in 1985, Soviet scientists created a theory of self-executing directions (also known as “semantic modeling”). Academics J.L. Yershov, S.S. Goncharov and Dr. Sviridenko figured out a way to bridge the gap in understanding between human and machine.
Here’s how.
Semantic Modeling, Explained
Here’s how Yershov, Goncharov, Sviridenko et al solved the key problem facing A.I 1.0 today.
Imagine a simple command – say, a mother telling her sun to go outside, stay in the neighbourhood and come back before 21:00.
This is a simple, logical command that any person can understand. It’s also the kind of command we can give to an A.I using what’s called logic programming.
The problem is that today, A.I 1.0 doesn’t use logic programming. Instead, it uses algorithms that look less like “go take a walk” and more like:
- Exit building and walk 5 meters in a straight line
- If you encounter a pet or person, stop for 10 seconds before continuing
- If you get more than 100 m away from home, also stop
- If you’ve stopped for more than 10 seconds and there’s nobody near you, start making your way back home
Can you imagine actually giving your child instructions like these? Of course not. They’re unnecessarily complex. And yet, all A.I 1.0 coding is done using algorithms like these rather than clear, logical instructions.
This is why we have the black box problem. This is why why struggle with overfitting. Our A.I doesn’t use logic that humans can understand; instead, it uses immensely complex algorithm combinations that are beyond our understanding.
This is where semantic modeling comes in.
With semantic modeling, we can give instructions that are clear to both A.Is and all humans. We can tell a computer to “go play outside without leaving the neighborhood, and to be back before 21:00”. In return, our A.I 2.0 will give us external predicates (also known as Oracle data).
This way, semantic modeling lets A.I understand any logical instructions explained in plain English. This solves the black box problem by bridging the human-machine language gap, and has another important advantage.
With semantic modeling, all existing plain-English contracts can be converted into A.I-operated smart contracts. All you need to do is scan and proofread them. Once you do that, the A.I takes over. Here’s an example of how this might work:
You’re about to get credit from your bank. You take the contract back home and give it to a physical robot that scans and processes it. After several seconds, the robot tells you that points 55 and 123.6 contradict each other, increasing your interest rate for no good reason. It adds that if you opt into the credit offer, you will have to pay extra taxes because the legal system changed a week ago.
Making an app like this with A.I 1.0 is difficult if not impossible. But with semantic modeling and A.I 2.0, this robot becomes very real.
The only question is, how can we use the mathematical theories that make this possible in practice?
Well, in practice, this kind of logic programming requires a semantic machine that can execute semantic contracts (automations). That’s what we’re doing with our project: KIRIK http://bit.ly/2Ke0sWo
With Kirik, we may see A.I 2.0 in the immediate future. As for A.I 3.0 – that will happen when robots can self-reflect and correct their own semantic contracts (without breaking the rules we give them).
To learn more about our project, visit our website at kirik.io, download the whitepaper and join our Telegram group. Thank you for reading!

Geef een reactie
Je moet inloggen om een reactie te kunnen plaatsen.